Another Susan sequence to show how the output can be tweaked. I start with cropping the original 3D render, as AI loses quality if the image is large in scale and better at close ups.
I identify the features for the AI: long brown hair, grey dress, black belt, torn pantyhose, quicksand, desert, etc. I let the AI do its first impression.
Not bad. I want to be a little closer to the character model's state, so I paint over the arms and add "torn sleeve" to the prompts.
Resulting in this.
Wanting to fix the dress up, I paint over the chest. I also add "pockets" to the prompt to reach this output:
At this point I could go even further and tweak the environment, background, maybe add more intensity to the facial expression and texture, but otherwise I think I've gotten close to what I want for the costume.
Viridian's AI Experiments
-
Viridian
- Posts: 1590
- Joined: Wed Apr 15, 2009 10:03 am
Re: Viridian's AI Experiments
You do not have the required permissions to view the files attached to this post.
Viridian @ deviantART: http://viridianqs.deviantart.com/
-
Theo

- Posts: 700
- Joined: Sat Feb 13, 2021 4:12 am
- Location: Sinking Fantasyland
Re: Viridian's AI Experiments
Wow, I didn’t realize there was that much to it; I’ll have to read it over a few more times before it makes sense (I’m a little slow on the uptake), but the results you’re getting are looking better and better. My first attempts at creating some images a month or so ago weren’t worth the time to post.
Thank you for the detailed explanation of your process! I’ll try to mess around more with AI images at some point, but for now, I’ll continue to enjoy your posts
Thank you for the detailed explanation of your process! I’ll try to mess around more with AI images at some point, but for now, I’ll continue to enjoy your posts
Finally broke down and went to see a psychologist. She told me I just have an overactive imagination—and it really excited her. We're going sinking next weekend. Theo's AI Quicksandbox New stuff every weekend (unless life gets in the way)
-
sixgunzloaded
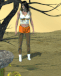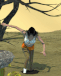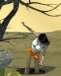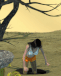
- Posts: 918
- Joined: Tue May 05, 2015 8:16 pm
Re: Viridian's AI Experiments
Definitely, thank you for sharing your process. Before you started posting them, I didn't even know this tool existed. It really is pretty fascinating, I think. Can it be used for animations?
As AI continues to advance and the program gets more intuitive, I can see it eventually becoming something of an interactive fantasy input/output device. Sort of like a Holodeck, but probably using a VR headset. A pipe dream, but that would be amazing.
In looking at the differences in each of the frames, I see where it followed your instructions, but I also noticed other changes to each output, such as moving her knees closer together, the different tear patterns in her dress and pantyhose, the darkening of the hose, her hand positions, the changing look of the qs, etc. Is that the AI coming up with those or user input?
As AI continues to advance and the program gets more intuitive, I can see it eventually becoming something of an interactive fantasy input/output device. Sort of like a Holodeck, but probably using a VR headset. A pipe dream, but that would be amazing.
In looking at the differences in each of the frames, I see where it followed your instructions, but I also noticed other changes to each output, such as moving her knees closer together, the different tear patterns in her dress and pantyhose, the darkening of the hose, her hand positions, the changing look of the qs, etc. Is that the AI coming up with those or user input?
How long did Tarzan watch before deciding to save Jill..?
-
Viridian
- Posts: 1590
- Joined: Wed Apr 15, 2009 10:03 am
Re: Viridian's AI Experiments
sixgunzloaded wrote:Definitely, thank you for sharing your process. Before you started posting them, I didn't even know this tool existed. It really is pretty fascinating, I think. Can it be used for animations?
Largely, no. I've seen some creators creating what is essentially a flipbook using the best matching AI generated images, but it's not an animation tool and the inconsistencies between each image make it impossible to create a fluid, cohesive animation. It's definitely lacking the tools of 3D rendering tools like Poser, where you can move models around. It's straight 2D illustrations.
As AI continues to advance and the program gets more intuitive, I can see it eventually becoming something of an interactive fantasy input/output device. Sort of like a Holodeck, but probably using a VR headset. A pipe dream, but that would be amazing.
I doubt it will get more intuitive. Part of what makes the really good images come out is knowledge of how to use the tool. I'm actually using perhaps the most simple interface - others do a lot more customisation with other diffusion models. Like with using something like Photoshop, the more you know how to tweak the input, the more control you have over the output. But yes, it's certainly been a "holodeck" experience for me in many ways.
In looking at the differences in each of the frames, I see where it followed your instructions, but I also noticed other changes to each output, such as moving her knees closer together, the different tear patterns in her dress and pantyhose, the darkening of the hose, her hand positions, the changing look of the qs, etc. Is that the AI coming up with those or user input?
Think of AI generations as rolling dice. Each time you create a new image, you roll every single part of the image. In the most basic terms, this depends on how much "creativity" you give to the AI to interpret the prompt. When using an image reference, you can slide the meter to give it more or less creativity and licence to depart from the source material. I normally run at around 55% (0.55 ish).
As we've done so far, here's the experiment with a new piece. I start with a raw text-only prompt, which gives me arguably the best image of the lot.
I then go from 0.25, then 0.5, then 0.75, and 0.99
The change aren't so dramatic because the base is already the same style as my desired output. So at low "strength" settings, it deviates very little, but it still "rolls" the specific items to have a different output - same mud texture, but slightly different bubbles/rocks in the background, different nipple colouration, etc. At the higher strength settings, it interprets the pose more liberally.
You do not have the required permissions to view the files attached to this post.
Viridian @ deviantART: http://viridianqs.deviantart.com/
-
Viridian
- Posts: 1590
- Joined: Wed Apr 15, 2009 10:03 am
Re: Viridian's AI Experiments
Things get a lot more radical when you have the source material as a completely different style. Using my own piece of art, we do the same 0.25 to 0.99 test.
As I said earlier, this gives the AI more freedom to interpret what it "sees" in the source material. The floatation aid is retained at lower strength, but at higher strength it reads it as if it is a leg and shapes the rest of the image around that anatomy. At max strength it moves away from my prompt and creates is own version of what I specified.
So using image to prompt means getting the right rough output, then tweaking the settings so that you minimise variables. However, you're still going to get a different output each time even with the same settings. The AI "reinterprets" the prompt with each generation. it doesn't pick and choose what to keep.
As I said earlier, this gives the AI more freedom to interpret what it "sees" in the source material. The floatation aid is retained at lower strength, but at higher strength it reads it as if it is a leg and shapes the rest of the image around that anatomy. At max strength it moves away from my prompt and creates is own version of what I specified.
So using image to prompt means getting the right rough output, then tweaking the settings so that you minimise variables. However, you're still going to get a different output each time even with the same settings. The AI "reinterprets" the prompt with each generation. it doesn't pick and choose what to keep.
You do not have the required permissions to view the files attached to this post.
Viridian @ deviantART: http://viridianqs.deviantart.com/
-
sixgunzloaded
- Posts: 918
- Joined: Tue May 05, 2015 8:16 pm
Re: Viridian's AI Experiments
Oh wow, it really takes quite a dramatic leap at 75% and 99% doesn't it? The rolling dice analogy clears it up for me. I can see where one might get really distracted playing around with those two percentages. Just seeing what it comes up with.
I'll bet it will get more intuitive though, as future versions come out. From what little I've read about it so far, it seems like a popular tool. Especially, if there's a freebie version to get people interested.
When you start off with a text-only piece, how many descriptors does it take and what sort do you use to generate an image like "base.png"? Did it come up with that on the first try?
I'll bet it will get more intuitive though, as future versions come out. From what little I've read about it so far, it seems like a popular tool. Especially, if there's a freebie version to get people interested.
When you start off with a text-only piece, how many descriptors does it take and what sort do you use to generate an image like "base.png"? Did it come up with that on the first try?
How long did Tarzan watch before deciding to save Jill..?
-
Viridian
- Posts: 1590
- Joined: Wed Apr 15, 2009 10:03 am
Re: Viridian's AI Experiments
sixgunzloaded wrote:Oh wow, it really takes quite a dramatic leap at 75% and 99% doesn't it? The rolling dice analogy clears it up for me. I can see where one might get really distracted playing around with those two percentages. Just seeing what it comes up with.
Even just running at the same strength produces different results. There's a certain gambling satisfaction from rolling good outputs. Though, it's easy to forget that you as the creator can manipulate the odds in your favour with the painting tools and changing the parameters, such as putting more emphasis on one specific tag and decreasing the priority of another.
When you start off with a text-only piece, how many descriptors does it take and what sort do you use to generate an image like "base.png"? Did it come up with that on the first try?
That one was literally the first try, so that was winning the pot right there. Often I might roll dozens of generations to get the right output. However, with the level of experimenting I've done, I've got my formula down to have more predictable and workable results.
For the descriptors: let's say it's "a lot". With the prompts, you can use prose or tags. For example, let's make the following:
"Blonde jungle explorer with long hair, wearing a green shirt, is sinking in quicksand in the jungle"
This is where many new creators are stuck: it doesn't give us what we 'want", just what the AI interprets. Also keep in mind that the app I use (NovelAI) is trained on anime models, so it more closely defaults to anime, whereas other AI apps will use realistic mashups.
This is where knowledge of which prompts are effective distinguishes new creators from the good ones. Firstly, I don't use prose - the AI doesn't treat prose any better than tags, and prose can be hard to understand for AI. What exactly is a "jungle explorer", or "quicksand", and so on? So I lay out the features of the piece: long straight blonde hair, detailed hair, dynamic hair, blue eyes, green shirt, large breasts, sinking in quicksand, deep mud, muddy, oozing mud, ripples, jungle background, etc.
We already have a very appealing output (three rerolls). As I said, NovelAI is an anime-based model, so the style is quite distinct. However, the style I use is photorealistic, so I add that tag in, run the prompt again, and after a few re-rolls to get something close to what I want:
We're getting much closer to my ideal QS illustration. Part of this is putting the right prompts - these give the AI direction on what it should include, and I can add weight to individual tags. For example, if I add "navel", the character probably won't be chest-deep since the instructions must include a navel, so you manipulate particular things to show or not show them. Same with the negative prompts - by including things like "legs" and "hips" in the negative prompts, the AI is less likely to include them, hence it "sinks" the character deeper in most outputs.
The full list out prompts is what AI creators tend to protect a bit more. When creators share work, there's always a demand to find out what the exact prompts and settings are. But like a secret recipe, creators often give vague descriptions but might not want to share what makes theirs special. The consistent quality of outputs is the result of many failed experiments.
You do not have the required permissions to view the files attached to this post.
Viridian @ deviantART: http://viridianqs.deviantart.com/
-
Viridian
- Posts: 1590
- Joined: Wed Apr 15, 2009 10:03 am
Re: Viridian's AI Experiments
But that's not what I've been producing, right? So let's steer this to the end. I want more detail, so I give it a big paint over and add a lot more tags: green collared shirt, cleavage, sweat, open mouth, etc.
I have to play with the strength slider a lot, since my base drawing is very shy on details and I need the AI to fill in more of the gaps to make it look realistic. So at around .75 and multiple attempts, I get this.
This is closer, so I drop the strength to around .65 and run it a few more times.
I'm not pleased with the mud texture, so I paint over it again and roll it on .75, since it won't recognise my scribble as mud.
After a few re-rolls with decreasing strength and it gets closer to my output, I get this:
NOT BAD. You can see where the AI has pushed some things more than others, like a survival of the fittest. Because I've been re-using specific samples to work from, I've inadvertently used outputs with more blue shades, so the AI keeps making the shirt blue. That, of course, can be fixed with some painting and prompting.
I have to play with the strength slider a lot, since my base drawing is very shy on details and I need the AI to fill in more of the gaps to make it look realistic. So at around .75 and multiple attempts, I get this.
This is closer, so I drop the strength to around .65 and run it a few more times.
I'm not pleased with the mud texture, so I paint over it again and roll it on .75, since it won't recognise my scribble as mud.
After a few re-rolls with decreasing strength and it gets closer to my output, I get this:
NOT BAD. You can see where the AI has pushed some things more than others, like a survival of the fittest. Because I've been re-using specific samples to work from, I've inadvertently used outputs with more blue shades, so the AI keeps making the shirt blue. That, of course, can be fixed with some painting and prompting.
You do not have the required permissions to view the files attached to this post.
Viridian @ deviantART: http://viridianqs.deviantart.com/
-
sixgunzloaded
- Posts: 918
- Joined: Tue May 05, 2015 8:16 pm
Re: Viridian's AI Experiments
I promise I won't ask for your secret recipe. lol I just find this new medium really fascinating. If I decide to play around with it at some point, it'll help to know the basics of how it works and what to expect. Hence, all the questions.  I appreciate the explanations!
I appreciate the explanations!
I wonder if having a larger or smaller vocabulary helps the AI more. Especially, if you start out with no reference pic. The blonde in the jungle demo had several nice outputs. I know you said prose is not better than tags but, can you pick and choose tags or specific words/phrases out of written prose? Is the AI capable of recognizing it? There are a lot of good qs stories out there that it would be neat to see even one or two interpreted frames depicted. Even if the results are different every time.
I wonder if having a larger or smaller vocabulary helps the AI more. Especially, if you start out with no reference pic. The blonde in the jungle demo had several nice outputs. I know you said prose is not better than tags but, can you pick and choose tags or specific words/phrases out of written prose? Is the AI capable of recognizing it? There are a lot of good qs stories out there that it would be neat to see even one or two interpreted frames depicted. Even if the results are different every time.
How long did Tarzan watch before deciding to save Jill..?
-
Viridian
- Posts: 1590
- Joined: Wed Apr 15, 2009 10:03 am
Re: Viridian's AI Experiments
sixgunzloaded wrote:I wonder if having a larger or smaller vocabulary helps the AI more.
Basically speaking, AI is more likely to recognise more commonly used terms because of how it is trained - and a lot of the words we use are actually vague and ambiguous. Certain things will trigger a "stronger" recognition while others are weaker or simply not recognised. Part of generating good outputs is knowing which tags are stronger or more likely to generate the desired output. Prose tends to be colourful and varied, which does not match the precision the AI expects.
The other problem is that prose is often convoluted and contradictory, especially when it comes to pronouns. We often use "he" or "she" in prose, but the AI has a hard time keeping track of who the line refers to. Additionally, prose contains a lot of unnecessary details that confuses the AI. The AI will try to include EVERYTHING in the prompt. Too much "clutter" and the AI will not put as much detail and weight into specific things that we want to focus more on as the viewer. Furthermore, good stories will scatter the details across the entire story, so a specific scene will assume the reader knows the context and can fill in the details with their mental memory, but the AI does not have this loaded into its memory unless you provide it.
There's also the simple matter of the prompt being too long. There's a maximum length that the AI can load.
Let's test this with an excerpt from Crypto's story, David's Day, using my current photorealistic settings.
But despite how it felt, the jungle was beautiful this morning with a light mist rising from the evaporating rain amongst the dense foliage. The wild birds were calling out while a band of monkeys traveled overhead. Then, as I wiped the sweat from my forehead, I suddenly heard a noise up ahead and stopped to listen. It sounded like the soft groan of a woman. I didn't know what it was for sure, but not wanting to stumble across the remote possibility a couple making love out in this beautiful yet dangerous wilderness, I started off in another direction. Then I heard it again. It was certainly a woman's voice, but there was a definite panic in her cry. I quickly headed in that direction.
The jungle was thick with lush, damp vegetation and full with the sounds of birds and monkeys which made locating the voice somewhat difficult. Eventually, I was able to determine that the cries of despair were coming from the open area just ahead. Breaking through the brush, I quickly came to an abrupt stop. About twelve feet ahead of me was a young woman mired up to her waist in the middle of a large, black bog... and I had come to just within a foot of its edge and joining her. Startled, she looked up at me. "Help me, please! I'm sinking," she said with concern in her trembling voice.
"Stay still; it's quicksand," I told her calmly as I took my pack off. She stopped struggling, but the thick mud continued to rise up her trim and shapely figure. The clearing created a sparse opening in the tree canopy above which let in a few rays of sunlight, illuminating her dangerous predicament. She was wearing a tight, dark green t-shirt with some sort of logo in yellow above and to the left of her full, round breasts. Her short, dark brown hair cascaded about her shoulders, damp with humidity. Even half submerged in this expanse of boggy ground, I could tell she was an attractive woman. Judging from the path of churned up mud, she must have entered from the opposite side and tried to continue across. Unfortunately, she had only gotten herself seriously bogged down in the middle of this treacherous morass of liquid earth.
The immediate problem was the length. The AI can't work with that chunk. I had to trim a lot of irrelevant details, dialogue, etc. You quickly realise that our language is very repetitive and full of filler, which does not benefit the AI generation. With that trimmed, here are three outputs.
You can tick off the items that it gets.
Quicksand gets a pass - I didn't use my special blend of quicksand tags and the AI can't really get it on its own, so that can be fixed.
Jungle - 100%. Simply amazing, vibrant background that I probably would not have done myself.
Character - hair generally good, kind of dark in the hair but pretty much right; definitely gets the breast department right; struggles a lot with the shirt colour, but the logo in the first picture is spot on. These present workable outputs.
In contrast, here's my output from my tags: medium brown hair, green t-shirt, large round breasts, lush jungle background, open mouth, scared, covered nipples + my blend of QS tags.
No painting or post-editing. I did include a logo tag, but it never generated one. I also had some outputs that did not include any clothing (likely because of the emphasis on breasts, hence making my character topless) and some wrong-colour outputs (black shirt), but it got the green most of the time.
You do not have the required permissions to view the files attached to this post.
Viridian @ deviantART: http://viridianqs.deviantart.com/
Who is online
Users browsing this forum: No registered users and 2 guests