Viridian's AI Experiments
-
Jinn

- Posts: 336
- Joined: Mon Apr 20, 2009 5:47 pm
- Contact:
Re: Viridian's AI Experiments
Jeebus! Yes, all day to these. Fantastic spread. For some reason I gravitate to the ones where she’s sort of lying down, like she’s trying to crawl out it she’s lost her balance and plopped down or something. Hot a/f. Bravo!
-
sixgunzloaded
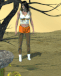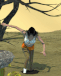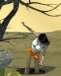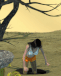
- Posts: 974
- Joined: Tue May 05, 2015 2:16 pm
Re: Viridian's AI Experiments
Viridian wrote:Well, here's another batch. Let's say the trick I learned was something that was counter-intuitive: I've been using photorealistic tags. However, photorealistic means art renders that are done in a photographic way. It ISN'T used to render actual photos. Tweaking the tags, I've shifted the results from 3D photorealistic renders to... photo renders.
I see. I guess you have to learn the grammatical semantics used by the different programs? Sorta like a game of word play? It actually sounds like a fun verbal 'treasure hunt', so to speak. I doubt I could coax out as much incredible and incredibly realistic variation as you and Jinn have done.
Again, this latest batch are astonishing! Thank you so much for these!
How long did Tarzan watch before deciding to save Jill..?
-
Viridian

- Posts: 1709
- Joined: Wed Apr 15, 2009 4:03 am
Re: Viridian's AI Experiments
New photo renders of the Tomb Raider 3 quicksand levels.
You do not have the required permissions to view the files attached to this post.
Viridian @ deviantART: http://viridianqs.deviantart.com/
-
Viridian
- Posts: 1709
- Joined: Wed Apr 15, 2009 4:03 am
Re: Viridian's AI Experiments
sixgunzloaded wrote:I see. I guess you have to learn the grammatical semantics used by the different programs? Sorta like a game of word play? It actually sounds like a fun verbal 'treasure hunt', so to speak. I doubt I could coax out as much incredible and incredibly realistic variation as you and Jinn have done. Again, this latest batch are astonishing! Thank you so much for these!
It's not so much about being semantic, but more about knowing what you're asking for. The "treasure hunt" is knowing the exact combination of prompts that will generate the exact textures. It's like a secret spice blend. A lot of beginners will be very vague and follow the default prompts, such as "supergirl in quicksand", but this is not very specific to what quicksand actually should look like, nor what medium the image is supposed to be. Is it a watercolor painting? A digital comic illustration? A 3D render? Or a photograph?
Using more "photography" prompts - NOT photorealistic or 3D render prompts - and I get results more like this:
We might be using similar Supergirl prompts, but our choice of AI model, along with our prompts, will have very different outputs. Even using Jinn's outputs in his thread and running them through my combination of models and prompts generates a very different appearance:
You can see the difference in Jinn's thread. Jinn uses photorealistic illustrations as the base, whereas I use photography as the base. Hence, my images tended to be more like Jinn's generations (with a more realistic model), whereas now they look more like actual photos.
You do not have the required permissions to view the files attached to this post.
Viridian @ deviantART: http://viridianqs.deviantart.com/
-
Jinn
- Posts: 336
- Joined: Mon Apr 20, 2009 5:47 pm
- Contact:
Re: Viridian's AI Experiments
Wow, awesome!! Great results, very interesting to see another perspective on the ones I did.
-
Acidtester
- Posts: 473
- Joined: Tue Apr 14, 2009 4:06 pm
Re: Viridian's AI Experiments
That one in the gold suit looks like the monsters knocked out all her teeth so if they put something in her mouth she can’t bite them. That’s some jailhouse tactics man, that’s hardcore!
If the system had one neck,
You know I'd gladly break it.
You know I'd gladly break it.
-
sixgunzloaded
- Posts: 974
- Joined: Tue May 05, 2015 2:16 pm
Re: Viridian's AI Experiments
Acidtester wrote:That one in the gold suit looks like the monsters knocked out all her teeth so if they put something in her mouth she can’t bite them. That’s some jailhouse tactics man, that’s hardcore!
Another beautiful set, Viridian! What sort of prompts do you use to get the mud to splash and churn around them like that? Unless you don't want to give away your technique of course...
How long did Tarzan watch before deciding to save Jill..?
-
Acidtester
- Posts: 473
- Joined: Tue Apr 14, 2009 4:06 pm
Re: Viridian's AI Experiments
Don’t get me wrong, these images look fucking amazing!!!
I still wake up everyday and check DA just to see viridian’s new work.
I still wake up everyday and check DA just to see viridian’s new work.
If the system had one neck,
You know I'd gladly break it.
You know I'd gladly break it.
-
Viridian
- Posts: 1709
- Joined: Wed Apr 15, 2009 4:03 am
Re: Viridian's AI Experiments
So the game has changed again. This is seriously a great time for us. Anyone experimenting with AI art now is going to be overwhelmed with what's now available. Even in the past two weeks, the ability to access more models and LORAs is a game-changer. I've barely been able to refine my outputs over the past month - I shifted from the "LifeLike" model to the more improved Realistic Vision V2, and the last few sets have been from Realistic Vision V3. Turns out I've been using old tech - Realistic Vision has V4 and V5 in the past month alone.
I switched from using "photorealistic" tags as the right photo prompts negate the need to specify it. Then I discovered the add_detail LORA.
For those who aren't familiar, LORAs are basically miniature training sets that narrow down the detail for a specific part of the image. This is commonly used for things like art styles and celeb faces, as the trainer can input the specific samples rather than rely on the AI's entire training set. The add_detail LORA basically adds that extra detail to everything - clothing, mud, skin textures.
I feel almost robbed because I've run the same outputs through my new prompts and models for better results, and THEN I discover I could've made them even better.
Then Stable Diffusion XL comes out, a much, much larger AI model. That's still being refined, and a lot of the prompts that worked with SD1.5 don't have the same clear results, but no doubt over the next few months that might push out even more detailed results. I haven't managed to get SDXL working with my current process, but I've re-run some recent creations with SD1.5 Realistic Vision V3 with the add_detail LORA.
I switched from using "photorealistic" tags as the right photo prompts negate the need to specify it. Then I discovered the add_detail LORA.
For those who aren't familiar, LORAs are basically miniature training sets that narrow down the detail for a specific part of the image. This is commonly used for things like art styles and celeb faces, as the trainer can input the specific samples rather than rely on the AI's entire training set. The add_detail LORA basically adds that extra detail to everything - clothing, mud, skin textures.
I feel almost robbed because I've run the same outputs through my new prompts and models for better results, and THEN I discover I could've made them even better.
Then Stable Diffusion XL comes out, a much, much larger AI model. That's still being refined, and a lot of the prompts that worked with SD1.5 don't have the same clear results, but no doubt over the next few months that might push out even more detailed results. I haven't managed to get SDXL working with my current process, but I've re-run some recent creations with SD1.5 Realistic Vision V3 with the add_detail LORA.
You do not have the required permissions to view the files attached to this post.
Viridian @ deviantART: http://viridianqs.deviantart.com/
-
Viridian
- Posts: 1709
- Joined: Wed Apr 15, 2009 4:03 am
Re: Viridian's AI Experiments
Putting together a sampler of some of our characters, probably the best quality photo AI images with the current tools.
You do not have the required permissions to view the files attached to this post.
Viridian @ deviantART: http://viridianqs.deviantart.com/
Who is online
Users browsing this forum: No registered users and 2 guests